В современных сетях надежность стоит на первом месте. Одно нештатное событие, и связь с критическими сервисами может прерваться на минуты или часы. Автоматическое переключение на резервный мультиплекс позволяет not only держать связь, но и минимизировать простой за счет мгновенного перенаправления трафика на запасной канал. В этой статье мы разложим по полочкам, как реализовать такую схему, какие элементы она включает и какие ошибки чаще всего возникают на практике.
- Зачем нужен резервный мультиплекс и как работает дублирование
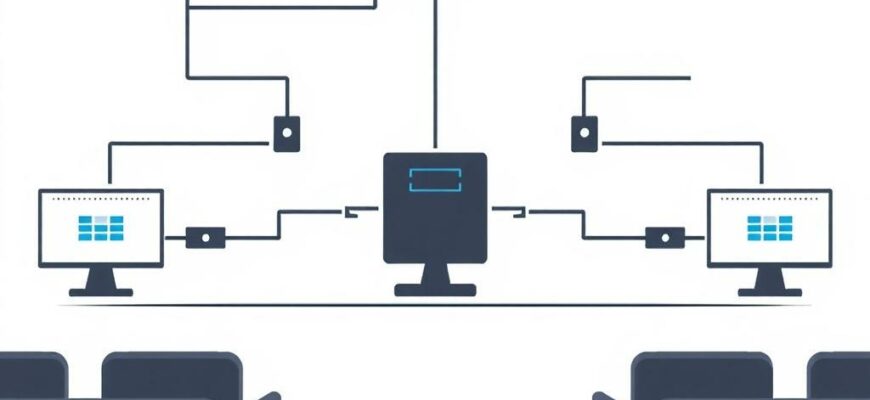
- Архитектура и принципы функционирования
- Основные элементы системы
- Мониторинг и детекция отказа
- Пошаговый план настройки
- Тестирование и валидация: как проверить работоспособность
- Типичные проблемы и способы устранения
- Личный опыт автора
- Итоги и советы по внедрению
Зачем нужен резервный мультиплекс и как работает дублирование
Во многих инфраструктурах мультиплексоры стоят в паре: один — основной, другой — резервный. Их задача — синхронная обработка потоков и мгновенное переключение при отказе первичного узла. Такой подход называется активной резервной схемой: резервный узел постоянно ждет команды переключения, но не перегружает сеть до тех пор, пока основной рабочий элемент не перестает отвечать. Это позволяет снизить потерю пакетов и резкие перегрузки на канале при временных сбоях.
Что именно обще принято считать «работой в автоматическом режиме»? Мониторинг состояния, детекция отказа и корректная маршрутизация трафика — вот три кита. Мониторинг может осуществляться через программные heartbeat-сообщения между узлами, через контроль доступности управляемых интерфейсов и через измерение задержек и потерь пакетов. Если детектор фиксирует нерабочее состояние, система инициирует переключение и переводит трафик на резервный мультиплекс без участия оператора. В итоге сервисы остаются доступны, а пользователи не ощущают простоев.
Архитектура и принципы функционирования
Типичная архитектура резервирования предполагает несколько уровней защиты. Первый уровень — физическое дублирование каналов и интерфейсов. Второй — логическое дублирование: управляющая логика держит ясную карту того, какой узел сейчас лидирует по обработке потока. Третий уровень — мониторинг качества канала: если показатели резко ухудшаются, система заранее переключается на запасной маршрут. Такая комбинация обеспечивает минимальные временные задержки и предсказуемость поведения.
Различают несколько вариантов реализации. В наиболее простом случае применяют схему активного резервирования: активный и резервный мультиплекс работают параллельно, однако трафик основного узла фактически является «окном» для переключения. При этом резервный узел настраивают так, чтобы он мог принимать все потоки без задержек, используя ту же полосу пропускания и те же параметры QoS. В более сложной конфигурации можно реализовать активный актив: оба мультиплексора обрабатывают трафик одновременно, а маршрутизатор — распределяет нагрузку и мгновенно снимает её с перегруженного узла.
Основные элементы системы
Ключевые компоненты в такой схеме — контроллер переключения, датчики состояния, средства мониторинга и сам мультиплексор. Контроллер отвечает за логику принятия решений: когда и на какой канал переключаться. Датчики состояния могут быть как простыми ping-проверками, так и продвинутыми протоколами детекции потерь и задержек. Мониторинг собирает данные и формирует сигнал о готовности узла к переносу трафика. Сам мультиплексор подстраивает маршруты и параметры QoS под текущее состояние сети.
Важно помнить про синхронизацию времени между узлами: без согласованного таймкода может возникнуть «зацикливание» и дубликаты потоков или потеря пакетов. Этап планирования должен учитывать совместимость протоколов управления, скорость обмена сообщениями между устройствами и требования к задержкам переключения. Все это влияет на реальный срок восстановления связи после сбоя.
Мониторинг и детекция отказа
Детекция отказа строится на двух китах: активной проверке доступности и анализе качества канала. В среднем достаточно периодичности проверки от 500 миллисекунд до нескольких секунд, чтобы переключение происходило незаметно для пользователя. В некоторых сценариях применяют механизмы watchdog и heartbeat-сообщения с нижнего уровня, чтобы исключить ложные срабатывания из-за временной задержки ответов.
Если система обнаруживает ухудшение параметров, она инициирует переключение и переводит управление трафиком на запасной узел. Важно заранее прописать пороги: например, если пакетная потеря достигает более 1–2% в течение трех последовательных контрольных периодов, можно считать канал неработоспособным. Такой подход снижает риск частых ложных переключений и позволяет сохранить стабильность работы сервисов.
Пошаговый план настройки
Первый шаг — определить цели и требования к устойчивости. Включите в задачу не только минимальные простои, но и соответствие SLA, латентности и QoS. Затем выберите архитектуру: активный резерв или активный актив. Ваш выбор будет зависеть от бюджета, требований к пропускной способности и уровня контроля над переключениями.
Следующий шаг — подготовка оборудования и ПО. Убедитесь, что обе стороны поддерживают совместимые режимы резервирования, одинаковые версии протоколов мониторинга и совместимую политику QoS. Не забывайте про лицензии на дополнительные функции, такие как расширенный мониторинг и управление трафиком. После этого переходите к настройке детекции отказа и логики переключения: задайте пороги, интервалы проверки, таймауты и правила направления трафика на резервный узел.
| Параметр | Описание | Пример значения |
|---|---|---|
| Период проверки | Как часто выполняется проверка доступности узла | 1000 мс |
| Порог потерь | Уровень потерь, после которого начинаем переключение | 2% |
| Время задержки переключения | Максимально допустимое время на переключение | 200–300 мс |
| Политика QoS | Как перераспределять при переключении | переназначение приоритетов |
После настройки технических параметров приходит фаза тестирования. Важно проверить, что переключение действительно происходит в заданный момент, и что резервный узел корректно принимает трафик. Пропишите логи и создайте тестовые сценарии: искусственный сбой основного мультиплексора, временная недоступность канала, имитация задержки связи. Результаты тестирования зафиксируйте в отчете и скорректируйте настройки, если заметны узкие места.
Тестирование и валидация: как проверить работоспособность
Тестирование лучше проводить в контролируемых условиях, чтобы не повредить реальный трафик. Начните с детекции отказа: временно отключите главный узел и проверьте, что трафик плавно перенаправляется на запасной. Важно оценить время переключения и качество обслуживания после переноса, включая задержки, джиттер и потери пакетов. Далее проведите тест на устойчивость: создайте несколько последовательных отказов и возвращений к основному узлу, чтобы убедиться, что система стабильно реагирует и не «заедает» на повторных отключениях.
Не забывайте про реальную эксплуатацию: после внедрения запустите мониторинг в течение недели, чтобы увидеть, как схема ведет себя в условиях пиковых нагрузок, сбоев на соседних узлах и изменении конфигурации сети. В результате вы получите критически важные данные: среднее время переключения, процент успешных переключений и влияние на сервисы. На основе этого можно скорректировать пороги и логику принятия решений.
Типичные проблемы и способы устранения
Чаще всего возникают ложные срабатывания из-за сбоев в сетевом оборудовании, несовместимых версий ПО и несогласованности таймингов. Решение — синхронизировать версии прошивок и регламентировать тесты на совместимость, заранее прописать сценарии на случай временной недоступности. Также встречаются задержки из-за медленного обновления ARP-таблиц или таблиц маршрутизации. Здесь помогает настройка коротких тайм-аутов и агрессивное обновление кэшей на переключателях и маршрутизаторах.
Еще одна распространенная проблема — неподходящие параметры QoS. При переключении приоритеты трафика могут неожиданно перераспределиться, что приводит к задержкам в критичных сервисах. В таком случае полезно зафиксировать политики перераспределения и протестировать их на условиях перегрузки, чтобы понять, как они работают на практике. И, наконец, не забывайте про резервное копирование конфигураций и документацию: без ясной карты настроек сложно быстро разбирать проблемы в полях.
Личный опыт автора
Работая над одним проектом, я столкнулся с задачей обеспечить непрерывность связи между головной локацией и двумя региональными центрами. Мы выбрали схему активного резервирования: оба мультиплексора держали каналы в рабочем состоянии, но основной поток трафика шёл через один узел. Детекция отказа строилась на пинг-тестах и синхронном обмене heartbeat-сообщениями между устройствами. Переключение происходило за порядок сотен миллисекунд, что было достаточно для непрерывности сервисов, включая VoIP и VPN.
В процессе внедрения мы столкнулись с ложными переключениями на фоне временных задержек связи. Проблему решили, подняв порог потерь и добавив временной фильтр на уровне контроллера: пересмотр порога, чтобы небольшие временные всплески не приводили к перестройке схемы. Также мы усилили кэш ARP на переходах и зафиксировали шаги переключения в документацию. Итогом стала более стабильная работа всей системы и возможность предугадать момент переключения без сюрпризов для пользователей.
Итоги и советы по внедрению
Если вам надо настроить автоматическое переключение на резервный мультиплекс, начните с четкого определения целей и отказоустойчивости. Прокомментируйте для себя: какие сервисы критичны, какие задержки допустимы, как быстро нужно переключение и какие ресурсы доступны для реализации резервирования. Выбор архитектуры должен основываться на ваших требованиях к пропускной способности и устойчивости сети.
Затем переходите к выбору оборудования и настройке детекции отказа. Важно синхронизировать версии ПО, согласовать тайминги и проверить совместимость протоколов. Настройте параметры мониторинга, тайм-ауты и правила маршрутизации так, чтобы переключение происходило плавно, без резких рывков. Не забывайте про тестирование: имитируйте сбои, проверяйте время переключения и качество обслуживания после переноса трафика.
Наконец, держите под рукой план эксплуатации и документацию. Включайте в неё конфигурации, сценарии тестирования, логи и контактные данные ответственных лиц. Это не просто бюрократия: когда что-то идет не так, ровная карта действий экономит часы и позволяет быстро вернуть сервисы в рабочий режим. Ваша цель — чтобы резерва всегда было достаточно, а переключение происходило настолько естественно, что пользователи scarcely заметят, что что-то изменилось.